Parallel sampling (e.g., Pass@k) promises substantial gains in test-time compute scaling—instead of one attempt, the model gets k independent tries to solve a problem. This approach is especially effective for tasks like mathematics and coding where solutions can be automatically verified.
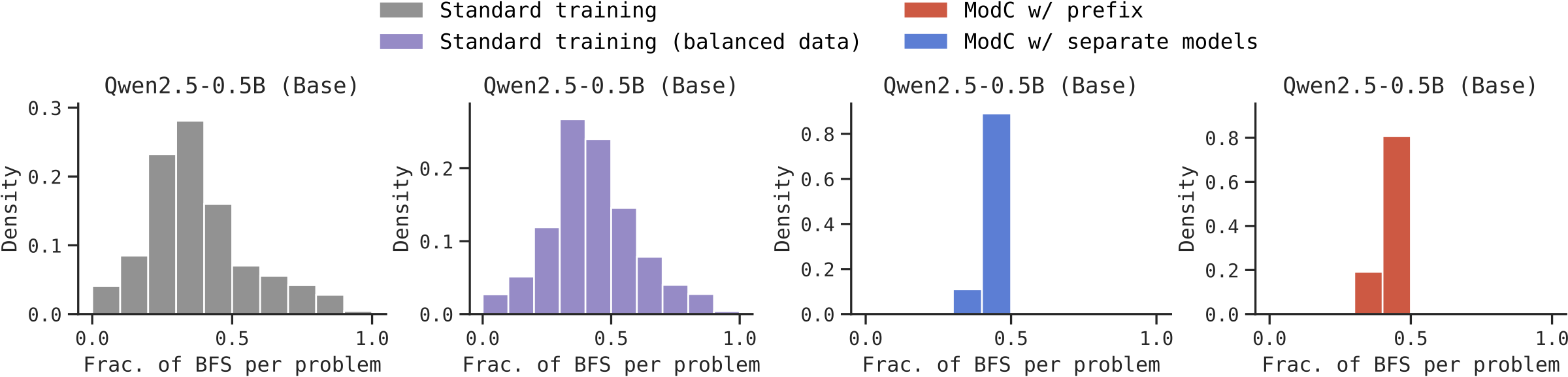
The Problem: Despite its promise, parallel scaling suffers from diversity collapse—models concentrate on a few dominant modes and repeated samples produce the same mistakes. As a result:
💡 Key Insight: Explicit mode allocation beats sampling from collapsed distributions
🧮 Mathematical Intuition
Even when a model is balanced across two modes with equal weights, explicitly allocating k/2 samples to each mode strictly outperforms drawing k samples from the mixture—whenever the modes have different success probabilities on an input. The advantage is especially pronounced when the dominant mode fails but a lower-probability one succeeds.
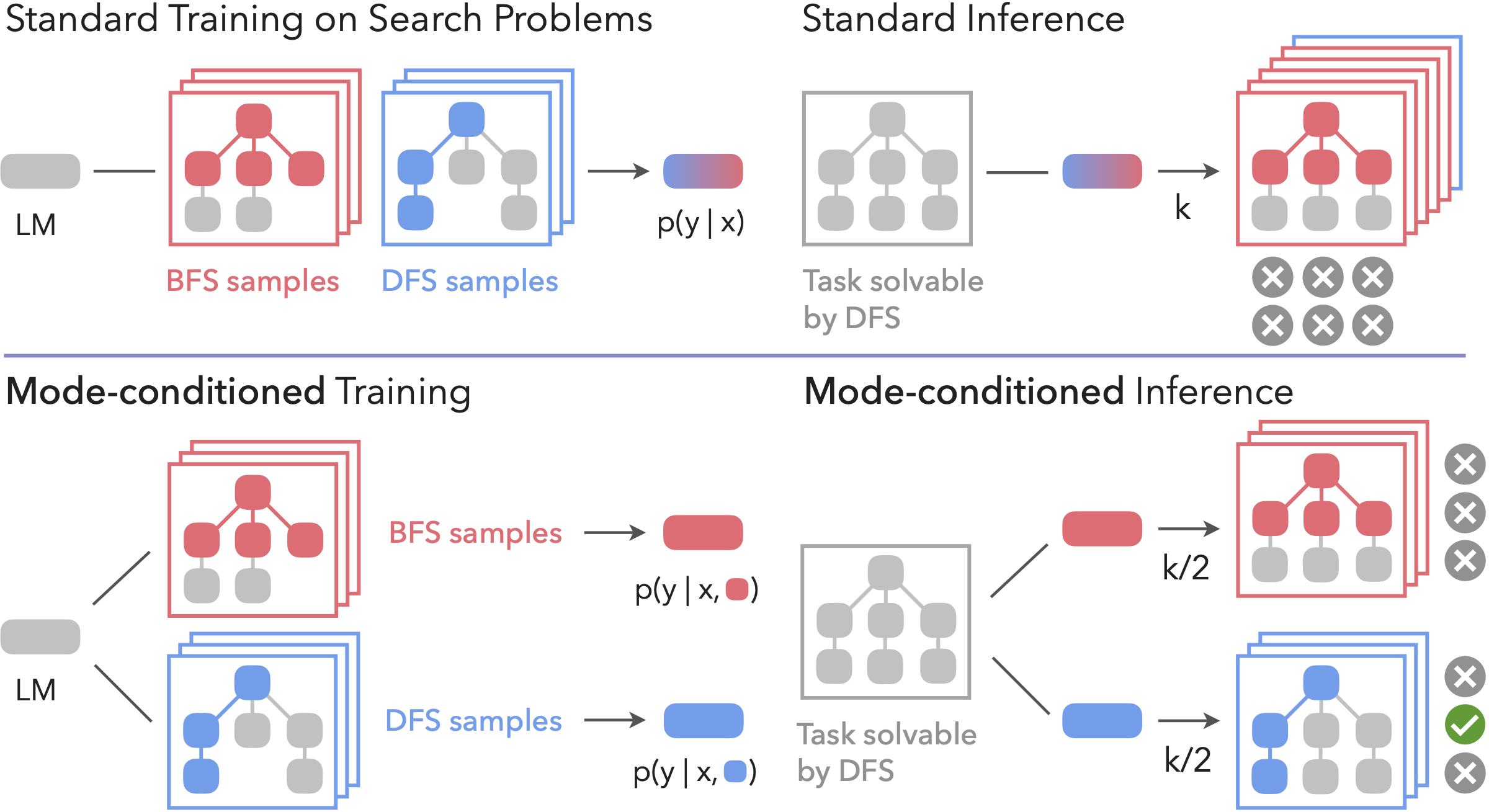
Given the challenges of diversity collapse, we propose mode-conditioning (ModC), a framework that explicitly structures test-time scaling around multiple reasoning modes. Rather than drawing repeatedly from a collapsed distribution, we enforce coverage across strategies by conditioning on modes.
Core Idea
Explicit Mode Allocation: Instead of sampling k times from a single mode, explicitly access N diverse modes and sample each k/N times.
Better Coverage: A problem that remains intractable under one distribution might be solvable under another, dramatically expanding the range of solvable problems.
Train distinct models, each specialized to a particular mode of reasoning. The training data is partitioned into subsets corresponding to different strategies, and a separate model is trained on each subset. At test time, the sampling budget is divided across the specialists (e.g., k/2 samples from each in the two-mode case).
✅ Advantages
Strong Separation: Ensures clear specialization with no interference between modes.
Reduced Correlated Errors: Different specialists fail on different problems, improving parallel scaling.
❌ Limitations
No Knowledge Sharing: Prevents transfer of common linguistic or mathematical foundations across modes.
Train a single model with explicit condition tokens (e.g., [Mode 1], [Mode 2]) prepended to each training example. The model learns to associate each prefix with a distinct reasoning strategy. At inference, balanced compute allocation is enforced by sampling evenly across the conditioning prefixes.
✅ Advantages
Knowledge Sharing: Enables transfer of shared knowledge across modes while maintaining specialization.
More Scalable: Requires training only a single model instead of multiple specialists.
❌ Limitations
Capacity Limits: May face challenges if trying to capture too many modes in a single model.
Imperfect Control: Model might not cleanly separate behaviors in all cases.
What if we don't know the modes in advance? Most real-world training data contains mixed modes but lacks explicit labels. We propose using gradient clustering to automatically discover and annotate modes in training data.
💡 Method
Key Intuition: Examples that induce similar parameter updates likely come from the same mode.
Algorithm:
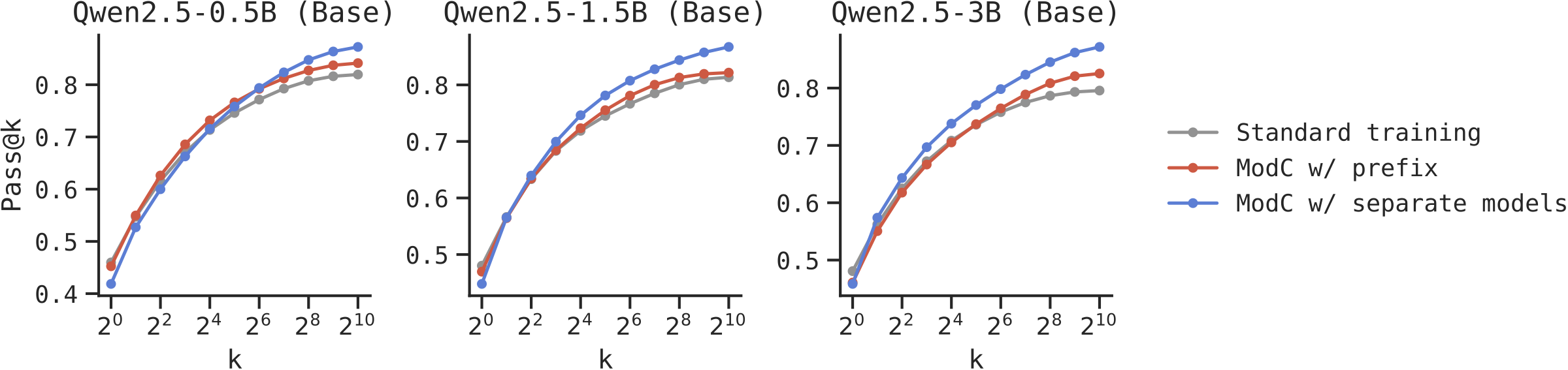
We first validate ModC on Countdown, a graph search task that can be solved using either depth-first search (DFS) or breadth-first search (BFS). Some problems are only solvable by DFS, others only by BFS—making mode coverage crucial.
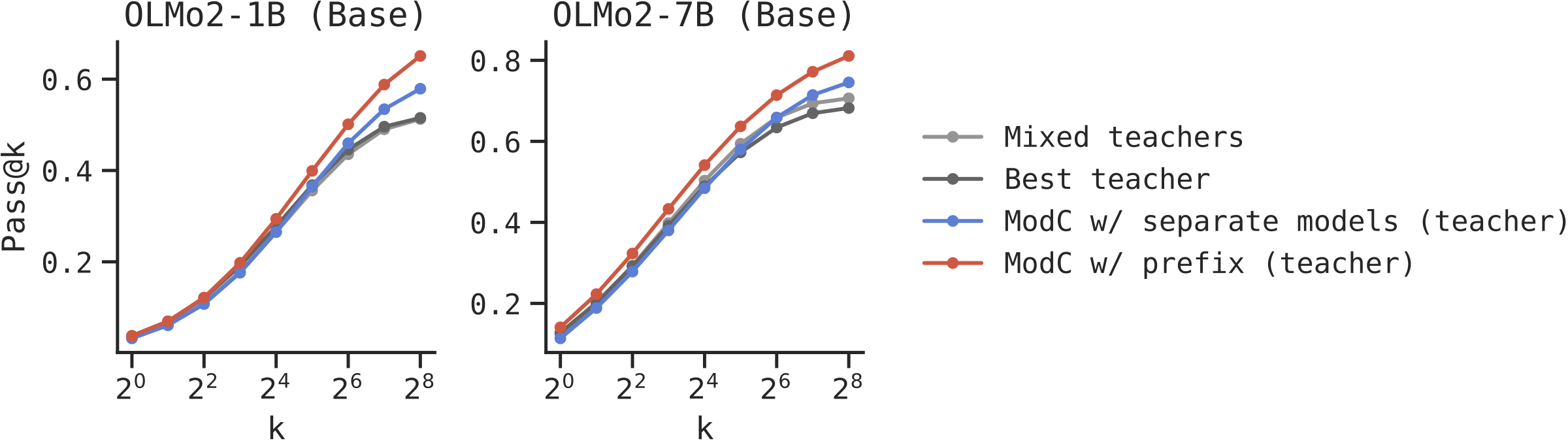
Short Chain-of-Thought: We apply ModC to distillation from two teachers (DeepSeek-R1 and GPT-OSS-120B) on the NuminaMath dataset, evaluated on MATH500.
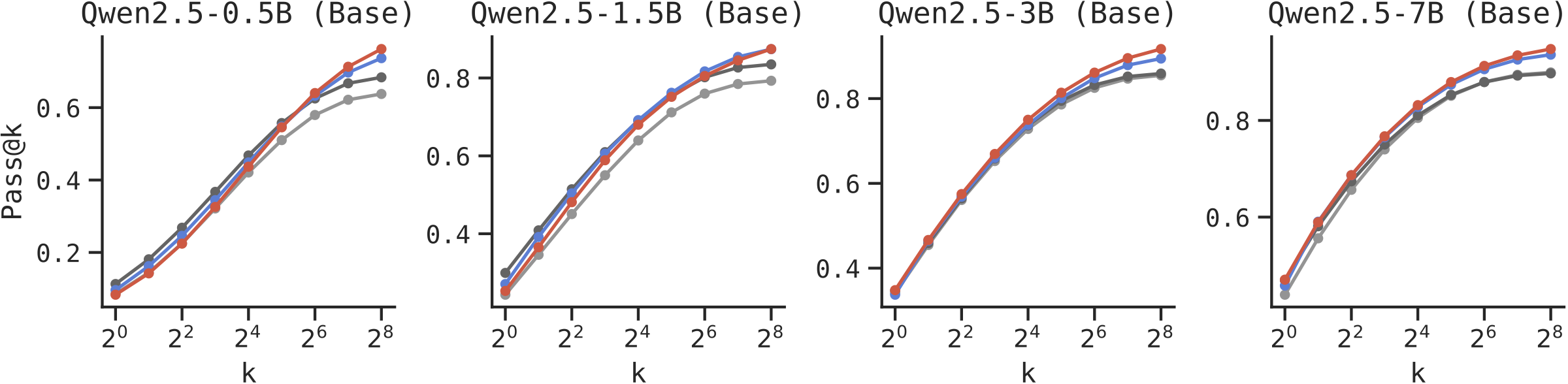
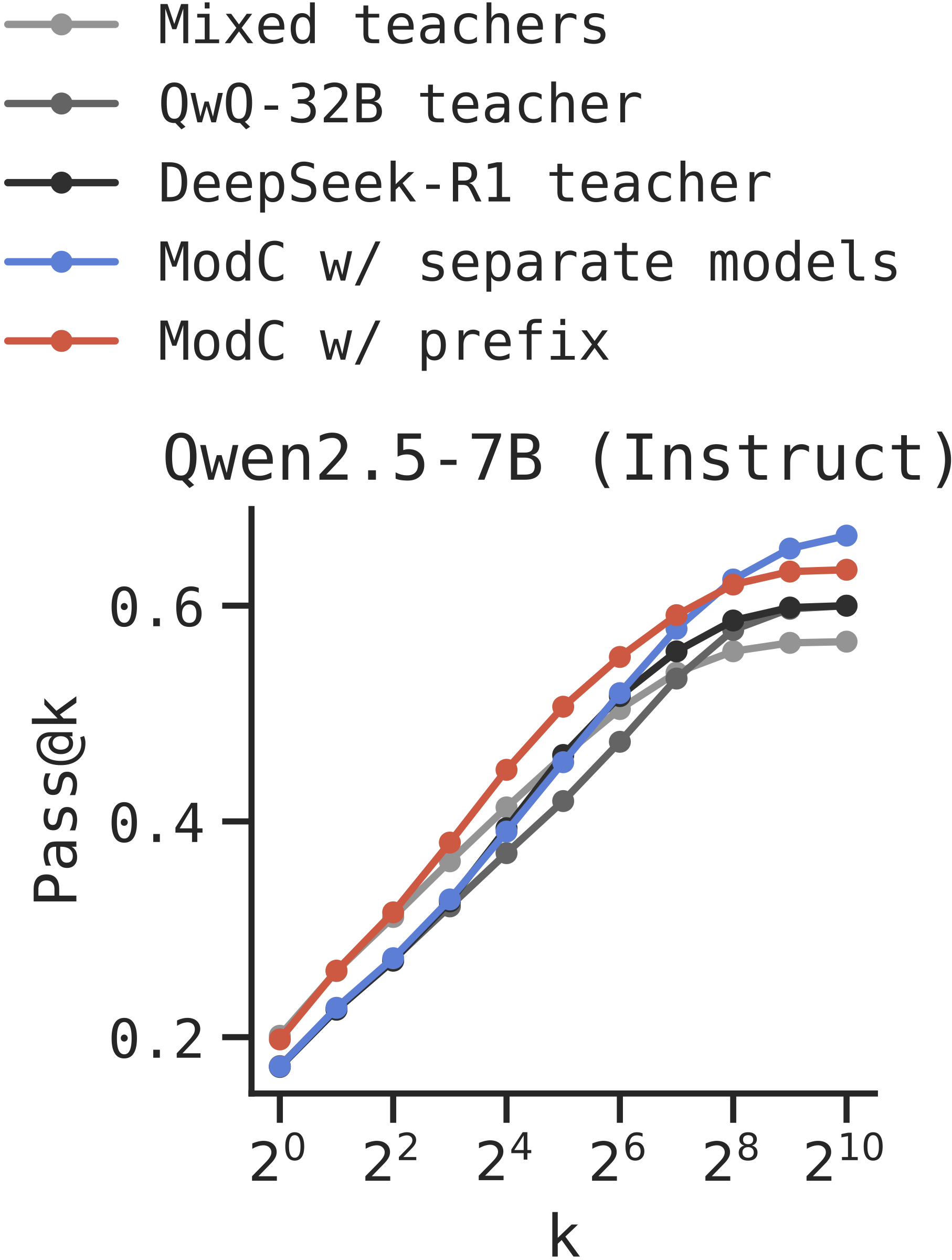
Long Chain-of-Thought: Using OpenThoughts dataset with QwQ-32B and DeepSeek-R1 teachers, evaluated on AIME 2025.
Can we discover modes automatically? We explore gradient clustering as a way to automatically discover meaningful modes in training data. Examples that induce similar parameter updates likely represent similar modes.
Validating on Multi-Teacher Data: We first validate gradient clustering on the short CoT dataset where ground-truth teacher labels exist. Gradient clustering achieves 98.7% F1 score in recovering teacher assignments, and more importantly, yields nearly identical test-time scaling benefits as using true teacher labels.
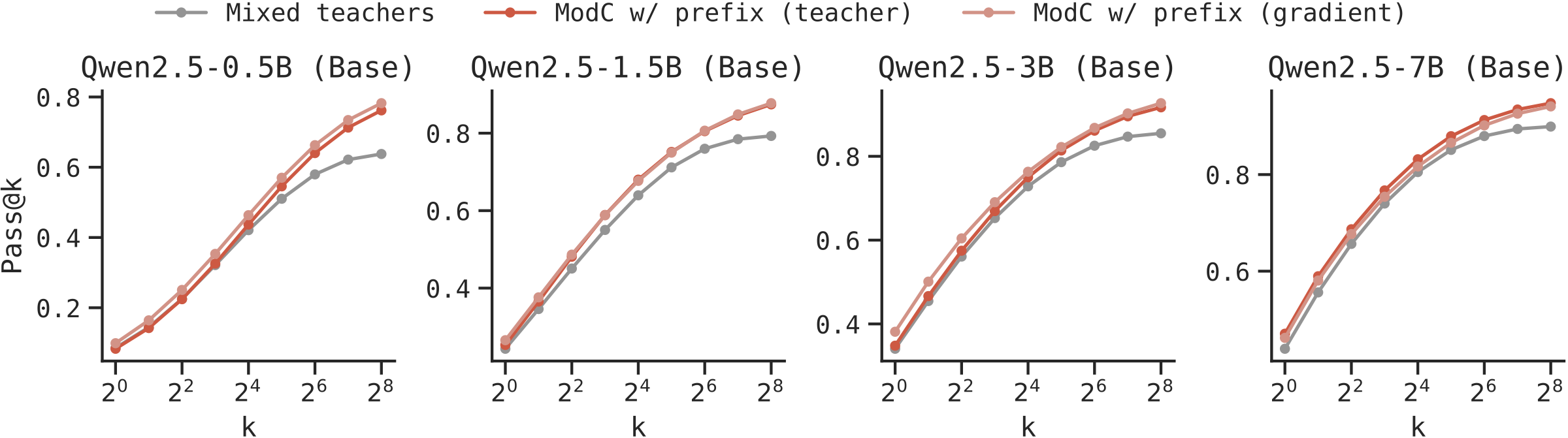
General Data Without Known Modes: We apply gradient clustering to NuminaMath, a diverse dataset where modes are unknown. ModC on automatically discovered modes yields significant improvements across model scales.
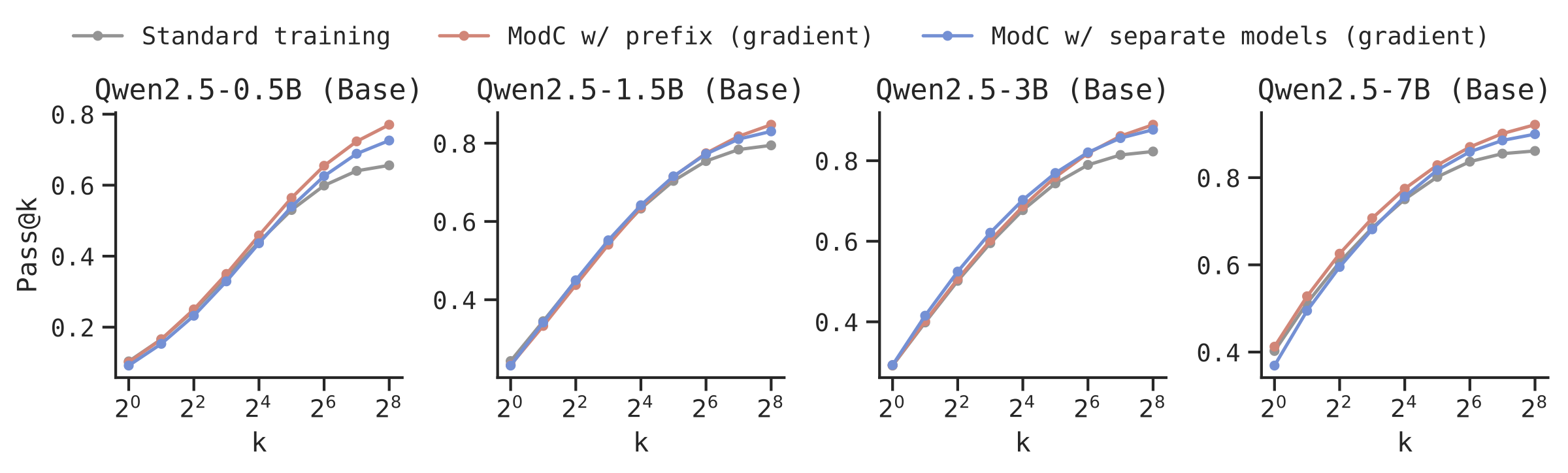
🎉 Key Takeaways
@article{
wu2025mode,
title={Mode-conditioning unlocks superior test-time compute scaling},
author={Chen Henry Wu and Sachin Goyal and Aditi Raghunathan},
journal={arXiv preprint},
year={2025}
}