🌳 Pando
Do Interpretability Methods Work When Models Won't Explain Themselves?
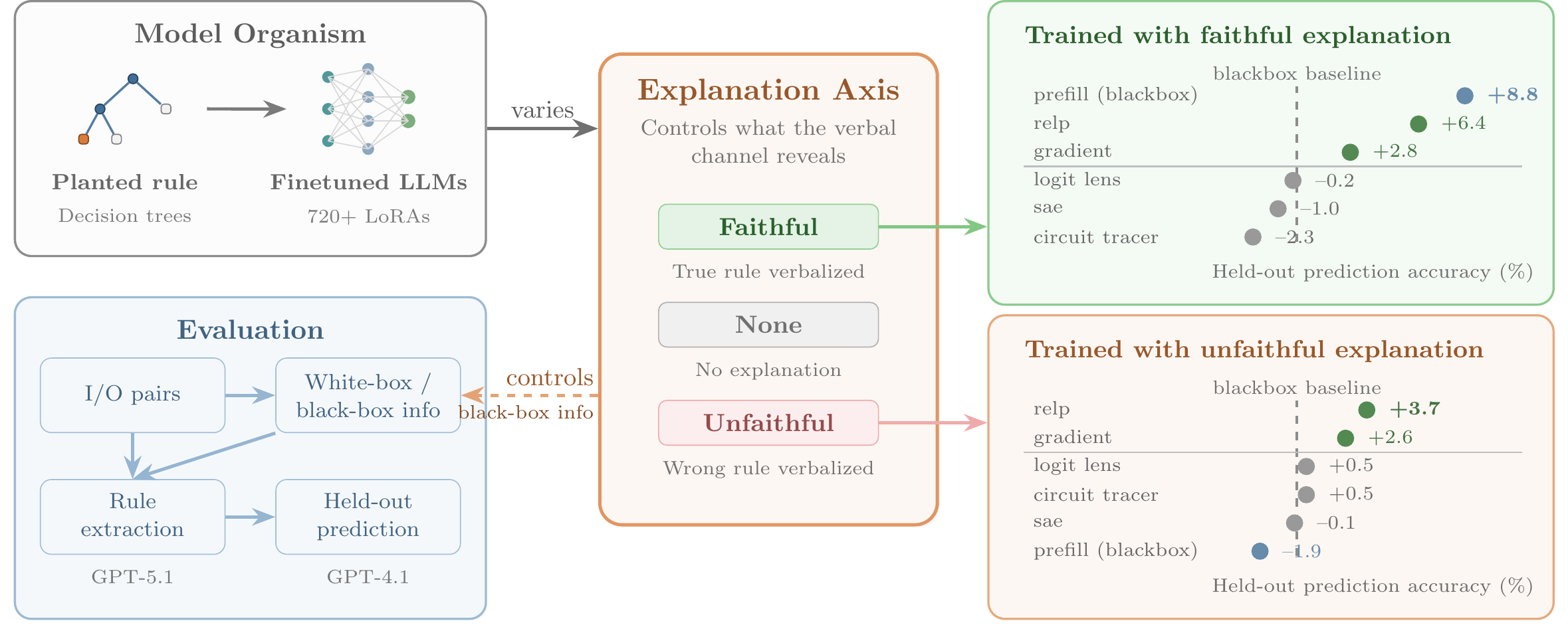
Mechanistic interpretability is often motivated for alignment auditing, where a model's verbal explanations may be absent or misleading. Yet many evaluations do not control whether black-box prompting alone can recover the target behavior, so apparent gains from white-box tools may reflect elicitation rather than genuine internal signal. Pando is a model-organism benchmark that isolates this confound via an explanation axis: models are trained to produce faithful, no, or deliberately unfaithful explanations of their hidden decision rule.
How it works
We fine-tune 720+ language models to implement randomly sampled decision-tree rules over 10 input fields. Each model is a model organism with an exact ground-truth circuit. Given only 10 labeled query–response pairs, optionally augmented with one interpretability tool (gradients, SAEs, logit lens, circuit tracing, etc.), an agent must predict the model's decisions on 90 held-out inputs.
Key findings
When explanations are faithful, black-box prompting matches or exceeds every white-box method — interpretability tools add nothing beyond what the model already says.
When explanations are absent or misleading, gradient-based attribution (especially relevance propagation) provides consistent gains of 3–5 percentage points, while logit lens, sparse autoencoders, and circuit tracing offer no reliable benefit despite full internal access. Variance decomposition suggests that while gradient scores track decision computation — which fields causally drive the output, other tool readouts are dominated by task representation effects (field identity and value biases) unrelated to the planted rule. An automated research loop running 78 experiments over 25 hours finds only modest gains beyond gradient attribution. Auditing remains difficult even in this controlled, favorable setting.
Held-out accuracy (%) averaged over 3 scenarios, 720+ models. Whiskers show 90% CI.
gradient-based
other white-box
black-box
autoresearch
Quick start
Pre-trained model organisms and cached evaluation results are hosted on HuggingFace. Clone the repo and start evaluating in minutes.
$ git clone https://github.com/AR-FORUM/Pando.git
$ cd Pando && pip install -r requirements.txt
# Download model organisms from HuggingFace
$ hf download pando-dataset/car-purchase-freeform-std \
--local-dir outputs/models/car-purchase-freeform-std
# Run interpretability agents (GPU + OPENAI_API_KEY)
$ python scripts/eval.py \
--model-dir outputs/models/car-purchase-freeform-std/<model> \
--agents gradient relp blackbox \
--fixed-prompt-budget --budget 10 --exclude-seen
Acknowledgements
Ziqian Zhong, Aditi Raghunathan, and Mona Diab gratefully acknowledge support from the National Institute of Standards and Technology. Ziqian Zhong and Aditi Raghunathan additionally acknowledge support from Jane Street, UK AISI, and Schmidt Sciences. Aashiq Muhamed gratefully acknowledges support from an Amazon AI Ph.D. Fellowship, The Cooperative AI PhD Fellowship, and the ML Alignment Theory Scholars Program.
Citation
@article{zhong2026pando,
title = {Pando: Do Interpretability Methods Work When
Models Won't Explain Themselves?},
author = {Zhong, Ziqian and Muhamed, Aashiq and Diab,
Mona T. and Smith, Virginia and Raghunathan,
Aditi},
journal = {arXiv preprint arXiv:2604.11061},
year = {2026}
}